
Intro - Why discuss yet another ORM (or the man who had a stain on his fancy suite)?
Betteridge's law of headlines suggests that a 'headline that ends in a question mark can be answered by the word NO'. Will this article follow this rule?
Imagine an elegant businessman (or woman) walking into a building, wearing a fancy tuxedo and a luxury watch wrapped around his palm. He smiles and waves all over to say hello while people around are starring admirably. You get a little closer, then shockingly, while standing nearby it's hard ignore a bold a dark stain over his white shirt. What a dissonance, suddenly all of that glamour is stained

Like this businessman, Node is highly capable and popular, and yet, in certain areas, its offering basket is stained with inferior offerings. One of these areas is the ORM space, "I wish we had something like (Java) hibernate or (.NET) Entity Framework" are common words being heard by Node developers. What about existing mature ORMs like TypeORM and Sequelize? We owe so much to these maintainers, and yet, the produced developer experience, the level of maintenance - just don't feel delightful, some may say even mediocre. At least so I believed before writing this article...
From time to time, a shiny new ORM is launched, and there is hope. Then soon it's realized that these new emerging projects are more of the same, if they survive. Until one day, Prisma ORM arrived surrounded with glamour: It's gaining tons of attention all over, producing fantastic content, being used by respectful frameworks and... raised 40,000,000$ (40 million) to build the next generation ORM - Is it the 'Ferrari' ORM we've been waiting for? Is it a game changer? If you're are the 'no ORM for me' type, will this one make you convert your religion?
In Practica.js (the Node.js starter based off Node.js best practices with 83,000 stars) we aim to make the best decisions for our users, the Prisma hype made us stop by for a second, evaluate its unique offering and conclude whether we should upgrade our toolbox?
This article is certainly not an 'ORM 101' but rather a spotlight on specific dimensions in which Prisma aims to shine or struggle. It's compared against the two most popular Node.js ORM - TypeORM and Sequelize. Why not others? Why other promising contenders like MikroORM weren't covered? Just because they are not as popular yet ana maturity is a critical trait of ORMs
Ready to explore how good Prisma is and whether you should throw away your current tools?
TOC
- Prisma basics in 3 minutes
- Things that are mostly the same
- Differentiation
- Closing
Prisma basics in 3 minutes
Just before delving into the strategic differences, for the benefit of those unfamiliar with Prisma - here is a quick 'hello-world' workflow with Prisma ORM. If you're already familiar with it - skipping to the next section sounds sensible. Simply put, Prisma dictates 3 key steps to get our ORM code working:
A. Define a model - Unlike almost any other ORM, Prisma brings a unique language (DSL) for modeling the database-to-code mapping. This proprietary syntax aims to express these models with minimum clutter (i.e., TypeScript generics and verbose code). Worried about having intellisense and validation? A well-crafted vscode extension gets you covered. In the following example, the prisma.schema file describes a DB with an Order table that has a one-to-many relation with a Country table:
// prisma.schema file
model Order {
id Int @id @default(autoincrement())
userId Int?
paymentTermsInDays Int?
deliveryAddress String? @db.VarChar(255)
country Country @relation(fields: [countryId], references: [id])
countryId Int
}
model Country {
id Int @id @default(autoincrement())
name String @db.VarChar(255)
Order Order[]
}
B. Generate the client code - Another unusual technique: to get the ORM code ready, one must invoke Prisma's CLI and ask for it:
npx prisma generate
Alternatively, if you wish to have your DB ready and the code generated with one command, just fire:
npx prisma migrate deploy
This will generate migration files that you can execute later in production and also the ORM client code
This will generate migration files that you can execute later in production and the TypeScript ORM code based on the model. The generated code location is defaulted under '[root]/NODE_MODULES/.prisma/client'. Every time the model changes, the code must get re-generated again. While most ORMs name this code 'repository' or 'entity' or 'active record', interestingly, Prisma calls it a 'client'. This shows part of its unique philosophy, which we will explore later
C. All good, use the client to interact with the DB - The generated client has a rich set of functions and types for your DB interactions. Just import the ORM/client code and use it:
import { PrismaClient } from '.prisma/client';
const prisma = new PrismaClient();
// A query example
await prisma.order.findMany({
where: {
paymentTermsInDays: 30,
},
orderBy: {
id: 'asc',
},
});
// Use the same client for insertion, deletion, updates, etc
That's the nuts and bolts of Prisma. Is it different and better?
What is the same?
When comparing options, before outlining differences, it's useful to state what is actually similar among these products. Here is a partial list of features that both TypeORM, Sequelize and Prisma support
- Casual queries with sorting, filtering, distinct, group by, 'upsert' (update or create),etc
- Raw queries
- Full text search
- Association/relations of any type (e.g., many to many, self-relation, etc)
- Aggregation queries
- Pagination
- CLI
- Transactions
- Migration & seeding
- Hooks/events (called middleware in Prisma)
- Connection pool
- Based on various community benchmarks, no dramatic performance differences
- All have huge amount of stars and downloads
Overall, I found TypeORM and Sequelize to be a little more feature rich. For example, the following features are not supported only in Prisma: GIS queries, DB-level custom constraints, DB replication, soft delete, caching, exclude queries and some more
With that, shall we focus on what really set them apart and make a difference
What is fundamentally different?
1. Type safety across the board
💁♂️ What is it about: ORM's life is not easier since the TypeScript rise, to say the least. The need to support typed models/queries/etc yields a lot of developers sweat. Sequelize, for example, struggles to stabilize a TypeScript interface and, by now offers 3 different syntaxes + one external library (sequelize-typescript) that offers yet another style. Look at the syntax below, this feels like an afterthought - a library that was not built for TypeScript and now tries to squeeze it in somehow. Despite the major investment, both Sequelize and TypeORM offer only partial type safety. Simple queries do return typed objects, but other common corner cases like attributes/projections leave you with brittle strings. Here are a few examples:
// Sequelize pesky TypeScript interface
type OrderAttributes = {
id: number,
price: number,
// other attributes...
};
type OrderCreationAttributes = Optional<OrderAttributes, 'id'>;
//😯 Isn't this a weird syntax?
class Order extends Model<InferAttributes<Order>, InferCreationAttributes<Order>> {
declare id: CreationOptional<number>;
declare price: number;
}
// Sequelize loose query types
await getOrderModel().findAll({
where: { noneExistingField: 'noneExistingValue' } //👍 TypeScript will warn here
attributes: ['none-existing-field', 'another-imaginary-column'], // No errors here although these columns do not exist
include: 'no-such-table', //😯 no errors here although this table doesn't exist
});
await getCountryModel().findByPk('price'); //😯 No errors here although the price column is not a primary key
// TypeORM loose query
const ordersOnSales: Post[] = await orderRepository.find({
where: { onSale: true }, //👍 TypeScript will warn here
select: ['id', 'price'],
})
console.log(ordersOnSales[0].userId); //😯 No errors here although the 'userId' column is not part of the returned object
Isn't it ironic that a library called TypeORM base its queries on strings?
🤔 How Prisma is different: It takes a totally different approach by generating per-project client code that is fully typed. This client embodies types for everything: every query, relations, sub-queries, everything (except migrations). While other ORMs struggles to infer types from discrete models (including associations that are declared in other files), Prisma's offline code generation is easier: It can look through the entire DB relations, use custom generation code and build an almost perfect TypeScript experience. Why 'almost' perfect? for some reason, Prisma advocates using plain SQL for migrations, which might result in a discrepancy between the code models and the DB schema. Other than that, this is how Prisma's client brings end to end type safety:
await prisma.order.findMany({
where: {
noneExistingField: 1, //👍 TypeScript error here
},
select: {
noneExistingRelation: { //👍 TypeScript error here
select: { id: true },
},
noneExistingField: true, //👍 TypeScript error here
},
});
await prisma.order.findUnique({
where: { price: 50 }, //👍 TypeScript error here
});
📊 How important: TypeScript support across the board is valuable for DX mostly. Luckily, we have another safety net: The project testing. Since tests are mandatory, having build-time type verification is important but not a life saver

🏆 Is Prisma doing better?: Definitely
2. Make you forget SQL
💁♂️ What is it about: Many avoid ORMs while preferring to interact with the DB using lower-level techniques. One of their arguments is against the efficiency of ORMs: Since the generated queries are not visible immediately to the developers, wasteful queries might get executed unknowingly. While all ORMs provide syntactic sugar over SQL, there are subtle differences in the level of abstraction. The more the ORM syntax resembles SQL, the more likely the developers will understand their own actions
For example, TypeORM's query builder looks like SQL broken into convenient functions
await createQueryBuilder('order')
.leftJoinAndSelect(
'order.userId',
'order.productId',
'country.name',
'country.id'
)
.getMany();
A developer who read this code 👆 is likely to infer that a join query between two tables will get executed
🤔 How Prisma is different: Prisma's mission statement is to simplify DB work, the following statement is taken from their homepage:
"We designed its API to be intuitive, both for SQL veterans and developers brand new to databases"
Being ambitious to appeal also to database layman, Prisma builds a syntax with a little bit higher abstraction, for example:
await prisma.order.findMany({
select: {
userId: true,
productId: true,
country: {
select: { name: true, id: true },
},
},
});
No join is reminded here also it fetches records from two related tables (order, and country). Could you guess what SQL is being produced here? how many queries? One right, a simple join? Surprise, actually, two queries are made. Prisma fires one query per-table here, as the join logic happens on the ORM client side (not inside the DB). But why?? in some cases, mostly where there is a lot of repetition in the DB cartesian join, querying each side of the relation is more efficient. But in other cases, it's not. Prisma arbitrarily chose what they believe will perform better in most cases. I checked, in my case it's slower than doing a one-join query on the DB side. As a developer, I would miss this deficiency due to the high-level syntax (no join is mentioned). My point is, Prisma sweet and simple syntax might be a bless for developer who are brand new to databases and aim to achieve a working solution in a short time. For the longer term, having full awareness of the DB interactions is helpful, other ORMs encourage this awareness a little better
📊 How important: Any ORM will hide SQL details from their users - without developer's awareness no ORM will save the day
🏆 Is Prisma doing better?: Not necessarily
3. Performance
💁♂️ What is it about: Speak to an ORM antagonist and you'll hear a common sensible argument: ORMs are much slower than a 'raw' approach. To an extent, this is a legit observation as most comparisons will show none-negligible differences between raw/query-builder and ORM.
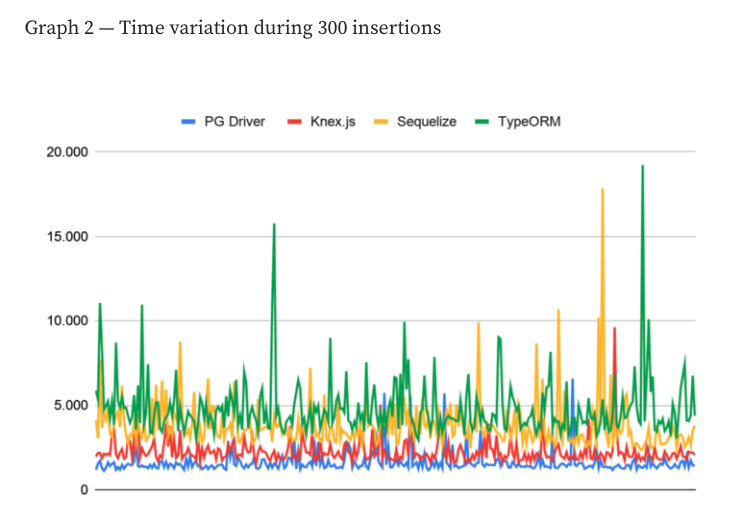 Example: a direct insert against the PG driver is much shorter Source
Example: a direct insert against the PG driver is much shorter Source
It should also be noted that these benchmarks don't tell the entire story - on top of raw queries, every solution must build a mapper layer that maps the raw data to JS objects, nest the results, cast types, and more. This work is included within every ORM but not shown in benchmarks for the raw option. In reality, every team which doesn't use ORM would have to build their own small "ORM", including a mapper, which will also impact performance
🤔 How Prisma is different: It was my hope to see a magic here, eating the ORM cake without counting the calories, seeing Prisma achieving an almost 'raw' query speed. I had some good and logical reasons for this hope: Prisma uses a DB client built with Rust. Theoretically, it could serialize to and nest objects faster (in reality, this happens on the JS side). It was also built from the ground up and could build on the knowledge pilled in ORM space for years. Also, since it returns POJOs only (see bullet 'No Active Record here!') - no time should be spent on decorating objects with ORM fields
You already got it, this hope was not fulfilled. Going with every community benchmark (one, two, three), Prisma at best is not faster than the average ORM. What is the reason? I can't tell exactly but it might be due the complicated system that must support Go, future languages, MongoDB and other non-relational DBs
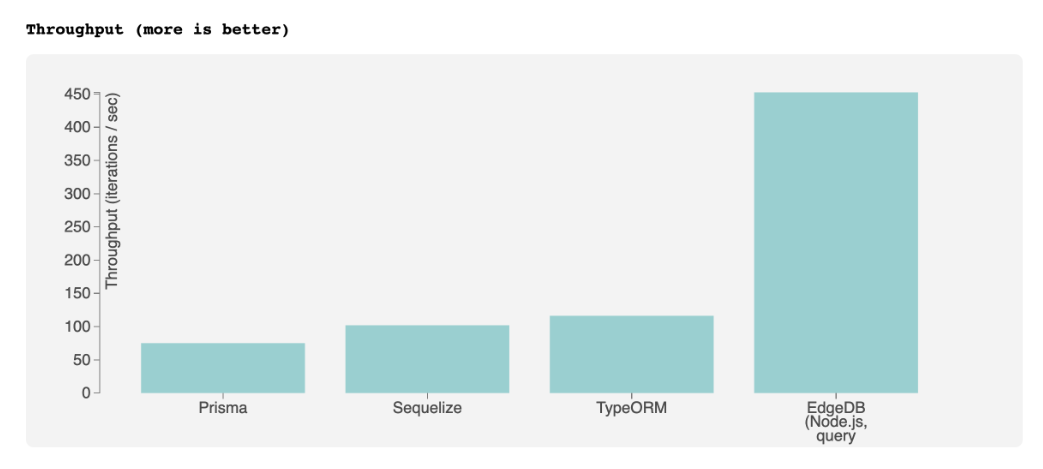 Example: Prisma is not faster than others. It should be noted that in other benchmarks Prisma scores higher and shows an 'average' performance Source
Example: Prisma is not faster than others. It should be noted that in other benchmarks Prisma scores higher and shows an 'average' performance Source
📊 How important: It's expected from ORM users to live peacefully with inferior performance, for many systems it won't make a great deal. With that, 10%-30% performance differences between various ORMs are not a key factor
🏆 Is Prisma doing better?: No
4. No active records here!
💁♂️ What is it about: Node in its early days was heavily inspired by Ruby (e.g., testing "describe"), many great patterns were embraced, Active Record is not among the successful ones. What is this pattern about in a nutshell? say you deal with Orders in your system, with Active Record an Order object/class will hold both the entity properties, possible also some of the logic functions and also CRUD functions. Many find this pattern to be awful, why? ideally, when coding some logic/flow, one should not keep her mind busy with side effects and DB narratives. It also might be that accessing some property unconsciously invokes a heavy DB call (i.e., lazy loading). If not enough, in case of heavy logic, unit tests might be in order (i.e., read 'selective unit tests') - it's going to be much harder to write unit tests against code that interacts with the DB. In fact, all of the respectable and popular architecture (e.g., DDD, clean, 3-tiers, etc) advocate to 'isolate the domain', separate the core/logic of the system from the surrounding technologies. With all of that said, both TypeORM and Sequelize support the Active Record pattern which is displayed in many examples within their documentation. Both also support other better patterns like the data mapper (see below), but they still open the door for doubtful patterns
// TypeORM active records 😟
@Entity()
class Order extends BaseEntity {
@PrimaryGeneratedColumn()
id: number
@Column()
price: number
@ManyToOne(() => Product, (product) => product.order)
products: Product[]
// Other columns here
}
function updateOrder(orderToUpdate: Order){
if(orderToUpdate.price > 100){
// some logic here
orderToUpdate.status = "approval";
orderToUpdate.save();
orderToUpdate.products.forEach((products) =>{
})
orderToUpdate.usedConnection = ?
}
}
🤔 How Prisma is different: The better alternative is the data mapper pattern. It acts as a bridge, an adapter, between simple object notations (domain objects with properties) to the DB language, typically SQL. Call it with a plain JS object, POJO, get it saved in the DB. Simple. It won't add functions to the result objects or do anything beyond returning pure data, no surprising side effects. In its purest sense, this is a DB-related utility and completely detached from the business logic. While both Sequelize and TypeORM support this, Prisma offers only this style - no room for mistakes.
// Prisma approach with a data mapper 👍
// This was generated automatically by Prisma
type Order {
id: number
price: number
products: Product[]
// Other columns here
}
function updateOrder(orderToUpdate: Order){
if(orderToUpdate.price > 100){
orderToUpdate.status = "approval";
prisma.order.update({ where: { id: orderToUpdate.id }, data: orderToUpdate });
// Side effect 👆, but an explicit one. The thoughtful coder will move this to another function. Since it's happening outside, mocking is possible 👍
products.forEach((products) =>{ // No lazy loading, the data is already here 👍
})
}
}
In Practica.js we take it one step further and put the prisma models within the "DAL" layer and wrap it with the repository pattern. You may glimpse into the code here, this is the business flow that calls the DAL layer
📊 How important: On the one hand, this is a key architectural principle to follow but the other hand most ORMs allow doing it right

🏆 Is Prisma doing better?: Yes!
5. Documentation and developer-experience
💁♂️ What is it about: TypeORM and Sequelize documentation is mediocre, though TypeORM is a little better. Based on my personal experience they do get a little better over the years, but still by no mean they deserve to be called "good" or "great". For example, if you seek to learn about 'raw queries' - Sequelize offers a very short page on this matter, TypeORM info is spread in multiple other pages. Looking to learn about pagination? Couldn't find Sequelize documents, TypeORM has some short explanation, 150 words only
🤔 How Prisma is different: Prisma documentation rocks! See their documents on similar topics: raw queries and pagingation, thousands of words, and dozens of code examples. The writing itself is also great, feels like some professional writers were involved
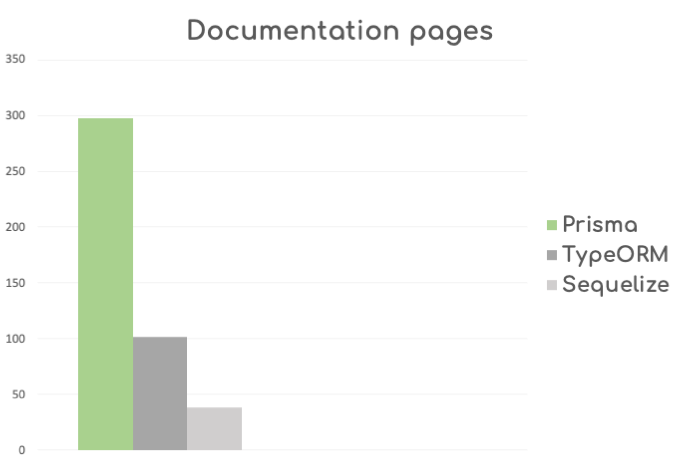
This chart above shows how comprehensive are Prisma docs (Obviously this by itself doesn't prove quality)
📊 How important: Great docs are a key to awareness and avoiding pitfalls
🏆 Is Prisma doing better?: You bet
6. Observability, metrics, and tracing
💁♂️ What is it about: Good chances are (say about 99.9%) that you'll find yourself diagnostic slow queries in production or any other DB-related quirks. What can you expect from traditional ORMs in terms of observability? Mostly logging. Sequelize provides both logging of query duration and programmatic access to the connection pool state ({size,available,using,waiting}). TypeORM provides only logging of queries that suppress a pre-defined duration threshold. This is better than nothing, but assuming you don't read production logs 24/7, you'd probably need more than logging - an alert to fire when things seem faulty. To achieve this, it's your responsibility to bridge this info to your preferred monitoring system. Another logging downside for this sake is verbosity - we need to emit tons of information to the logs when all we really care for is the average duration. Metrics can serve this purpose much better as we're about to see soon with Prisma
What if you need to dig into which specific part of the query is slow? unfortunately, there is no breakdown of the query phases duration - it's being left to you as a black-box
// Sequelize - logging various DB information
 Logging each query in order to realize trends and anomaly in the monitoring system
Logging each query in order to realize trends and anomaly in the monitoring system
🤔 How Prisma is different: Since Prisma targets also enterprises, it must bring strong ops capabilities. Beautifully, it packs support for both metrics and open telemetry tracing!. For metrics, it generates custom JSON with metric keys and values so anyone can adapt this to any monitoring system (e.g., CloudWatch, statsD, etc). On top of this, it produces out of the box metrics in Prometheus format (one of the most popular monitoring platforms). For example, the metric 'prisma_client_queries_duration_histogram_ms' provides the average query length in the system overtime. What is even more impressive is the support for open-tracing - it feeds your OpenTelemetry collector with spans that describe the various phases of every query. For example, it might help realize what is the bottleneck in the query pipeline: Is it the DB connection, the query itself or the serialization?
 Prisma visualizes the various query phases duration with open-telemtry
Prisma visualizes the various query phases duration with open-telemtry
🏆 Is Prisma doing better?: Definitely
📊 How important: Goes without words how impactful is observability, however filling the gap in other ORM will demand no more than a few days
7. Continuity - will it be here with us in 2024/2025
💁♂️ What is it about: We live quite peacefully with the risk of one of our dependencies to disappear. With ORM though, this risk demand special attention because our buy-in is higher (i.e., harder to replace) and maintaining it was proven to be harder. Just look at a handful of successful ORMs in the past: objection.js, waterline, bookshelf - all of these respectful project had 0 commits in the past month. The single maintainer of objection.js announced that he won't work the project anymore. This high churn rate is not surprising given the huge amount of moving parts to maintain, the gazillion corner cases and the modest 'budget' OSS projects live with. Looking at OpenCollective shows that Sequelize and TypeORM are funded with ~1500$ month in average. This is barely enough to cover a daily Starbucks cappuccino and croissant (6.95$ x 365) for 5 maintainers. Nothing contrasts this model more than a startup company that just raised its series B - Prisma is funded with 40,000,000$ (40 millions) and recruited 80 people! Should not this inspire us with high confidence about their continuity? I'll surprisingly suggest that quite the opposite is true
See, an OSS ORM has to go over one huge hump, but a startup company must pass through TWO. The OSS project will struggle to achieve the critical mass of features, including some high technical barriers (e.g., TypeScript support, ESM). This typically lasts years, but once it does - a project can focus mostly on maintenance and step out of the danger zone. The good news for TypeORM and Sequelize is that they already did! Both struggled to keep their heads above the water, there were rumors in the past that TypeORM is not maintained anymore, but they managed to go through this hump. I counted, both projects had approximately ~2000 PRs in the past 3 years! Going with repo-tracker, each see multiple commits every week. They both have vibrant traction, and the majority of features you would expect from an ORM. TypeORM even supports beyond-the-basics features like multi data source and caching. It's unlikely that now, once they reached the promise land - they will fade away. It might happen, there is no guarantee in the OSS galaxy, but the risk is low
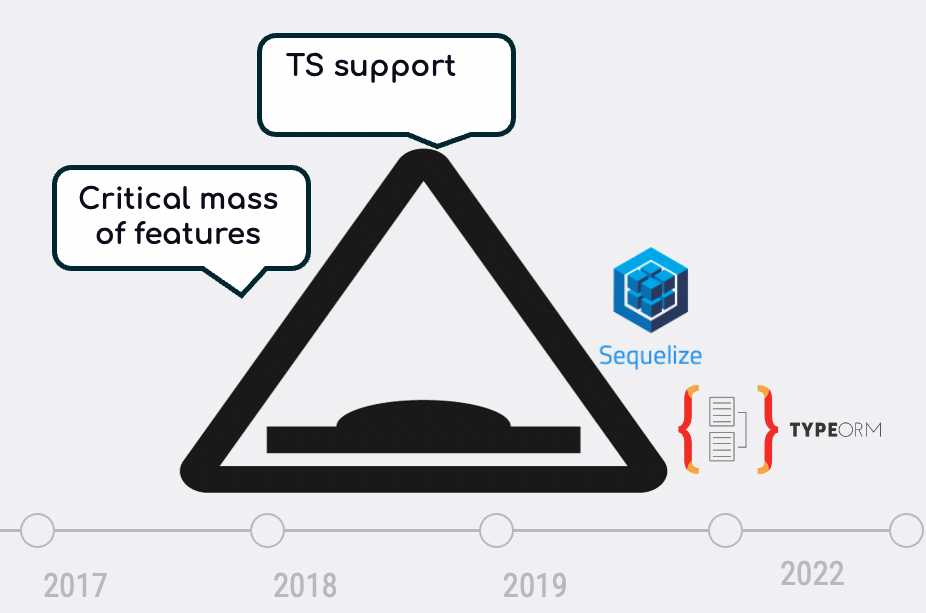
🤔 How Prisma is different: Prisma a little lags behind in terms of features, but with a budget of 40M$ - there are good reasons to believe that they will pass the first hump, achieving a critical mass of features. I'm more concerned with the second hump - showing revenues in 2 years or saying goodbye. As a company that is backed by venture capitals - the model is clear and cruel: In order to secure their next round, series B or C (depends whether the seed is counted), there must be a viable and proven business model. How do you 'sell' ORM? Prisma experiments with multiple products, none is mature yet or being paid for. How big is this risk? According to this startup companies success statistics, "About 65% of the Series A startups get series B, while 35% of the companies that get series A fail.". Since Prisma already gained a lot of love and adoption from the community, there success chances are higher than the average round A/B company, but even 20% or 10% chances to fade away is concerning
This is terrifying news - companies happily choose a young commercial OSS product without realizing that there are 10-30% chances for this product to disappear

Some of startup companies who seek a viable business model do not shut the doors rather change the product, the license or the free features. This is not my subjective business analysis, here are few examples: MongoDB changed their license, this is why the majority had to host their Mongo DB over a single vendor. Redis did something similar. What are the chances of Prisma pivoting to another type of product? It actually already happened before, Prisma 1 was mostly about graphQL client and server, it's now retired
It's just fair to mention the other potential path - most round B companies do succeed to qualify for the next round, when this happens even bigger money will be involved in building the 'Ferrari' of JavaScript ORMs. I'm surely crossing my fingers for these great people, at the same time we have to be conscious about our choices
📊 How important: As important as having to code again the entire DB layer in a big system

🏆 Is Prisma doing better?: Quite the opposite
Closing - what should you use now?
Before proposing my key take away - which is the primary ORM, let's repeat the key learning that were introduced here:
- 🥇 Prisma deserves a medal for its awesome DX, documentation, observability support and end-to-end TypeScript coverage
- 🤔 There are reasons to be concerned about Prisma's business continuity as a young startup without a viable business model. Also Prisma's abstract client syntax might blind developers a little more than other ORMs
- 🎩 The contenders, TypeORM and Sequelize, matured and doing quite well: both have merged thousand PRs in the past 3 years to become more stable, they keep introducing new releases (see repo-tracker), and for now holds more features than Prisma. Also, both show solid performance (for an ORM). Hats off to the maintainers!
Based on these observations, which should you pick? which ORM will we use for practica.js?
Prisma is an excellent addition to Node.js ORMs family, but not the hassle-free one tool to rule them all. It's a mixed bag of many delicious candies and a few gotchas. Wouldn't it grow to tick all the boxes? Maybe, but unlikely. Once built, it's too hard to dramatically change the syntax and engine performance. Then, during the writing and speaking with the community, including some Prisma enthusiasts, I realized that it doesn't aim to be the can-do-everything 'Ferrari'. Its positioning seems to resemble more a convenient family car with a solid engine and awesome user experience. In other words, it probably aims for the enterprise space where there is mostly demand for great DX, OK performance, and business-class support
In the end of this journey I see no dominant flawless 'Ferrari' ORM. I should probably change my perspective: Building ORM for the hectic modern JavaScript ecosystem is 10x harder than building a Java ORM back then in 2001. There is no stain in the shirt, it's a cool JavaScript swag. I learned to accept what we have, a rich set of features, tolerable performance, good enough for many systems. Need more? Don't use ORM. Nothing is going to change dramatically, it's now as good as it can be
When will it shine?
Surely use Prisma under these scenarios - If your data needs are rather simple; when time-to-market concern takes precedence over the data processing accuracy; when the DB is relatively small; if you're a mobile/frontend developer who is doing her first steps in the backend world; when there is a need for business-class support; AND when Prisma's long term business continuity risk is a non-issue for you
I'd probably prefer other options under these conditions - If the DB layer performance is a major concern; if you're savvy backend developer with solid SQL capabilities; when there is a need for fine grain control over the data layer. For all of these cases, Prisma might still work, but my primary choices would be using knex/TypeORM/Sequelize with a data-mapper style
Consequently, we love Prisma and add it behind flag (--orm=prisma) to Practica.js. At the same time, until some clouds will disappear, Sequelize will remain our default ORM